
robots 是站点与 spider 沟通的重要渠道,站点通过 robots 文件声明该网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用 robots.txt 文件。
什么是robots.txt
robots 是站点与 spider 沟通的重要渠道,站点通过 robots 文件声明该网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用 robots.txt 文件。
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
搜索引擎机器人访问网站时,首先会寻找站点根目录有没有 robots.txt文件,如果有这个文件就根据文件的内容确定收录范围,如果没有就按默认访问以及收录所有页面。另外,当搜索蜘蛛发现不存在robots.txt文件时,会产生一个404错误日志在服务器上,从而增加服务器的负担,因此为站点添加一个robots.txt文件还是很重要的。
SEO中的作用
从SEO角度来说,刚上线的网站,由于页面较少,robots.txt做不做都可以,但随着页面的增加,robots.txt的SEO作用就体现出来了,主要表现在以下几个方面。
- 优化搜索引擎机器人的爬行抓取
- 阻止恶意抓取,优化服务器资源
- 减少重复内容出现在搜索结果中
- 隐藏页面链接出现在搜索结果中
如何查看
如:https://www.npc.ink/robots.txt
访问此链接,即可看到本站的robots.txt文件。
如何设置
方法一:安装插件:XML Sitemap & Google News feeds,详见:

方法二: 新建一个名称为robots.txt文本文件,将相关内容放进去,然后上传到网站根目录即可。
放置什么
推荐放入以下内容:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-content/
Disallow: /wp-includes/
Disallow: /*/comment-page-*
Disallow: /*?replytocom=*
Disallow: /category/*/page/
Disallow: /tag/*/page/
Disallow: /*/trackback
Disallow: /feed
Disallow: /*/feed
Disallow: /comments/feed
Disallow: /?s=*
Disallow: /*/?s=*
Disallow: /*?*
Disallow: /attachment/
具体放啥需要你阅读以下文件后决定,以上仅为推荐。
各项作用
robots.txt的写法包括User-agent,Disallow,Allow和Crawl-delay。
- User-agent: 后面填你要针对的搜索引擎,*代表全部搜索引擎
- Disallow: 后面填你要禁止抓取的网站内容和文件夹,/做前缀
- Allow: 后面填你允许抓取的网站内容,文件夹和链接,/做前缀
- Crawl-delay: 后面填数字,意思是抓取延迟,小网站不建议使用
1、Disallow: /wp-admin/、Disallow: /wp-content/和Disallow: /wp-includes/
用于告诉搜索引擎不要抓取后台程序文件页面。
2、Disallow: /*/comment-page-*和Disallow: /*?replytocom=*
禁止搜索引擎抓取评论分页等相关链接。
3、Disallow: /category/*/page/和Disallow: /tag/*/page/
禁止搜索引擎抓取收录分类和标签的分页。
4、Disallow: /*/trackback
禁止搜索引擎抓取收录trackback等垃圾信息
5、Disallow: /feed、Disallow: /*/feed和Disallow: /comments/feed
禁止搜索引擎抓取收录feed链接,feed只用于订阅本站,与搜索引擎无关。
6、Disallow: /?s=*和Disallow: /*/?s=*
禁止搜索引擎抓取站内搜索结果
7、Disallow: /*?*
禁止搜索抓取动态页面
8、Disallow: /attachment/
禁止搜索引擎抓取附件页面,比如毫无意义的图片附件页面。
文件详解
robots文件往往放置于根目录下,包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
"<field>:<optional space><value><optionalspace>"
在该文件中可以使用#进行注解,具体使用方法和UNIX中的惯例一样。该文件中的记录通常以一行或多行User-agent开始,后面加上若干Disallow和Allow行,详细情况如下:
User-agent:该项的值用于描述搜索引擎robot的名字。在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会受到"robots.txt"的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则对任何robot均有效,在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。如果在"robots.txt"文件中,加入"User-agent:SomeBot"和若干Disallow、Allow行,那么名为"SomeBot"只受到"User-agent:SomeBot"后面的 Disallow和Allow行的限制。
Disallow:该项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会被 robot访问。例如"Disallow:/help"禁止robot访问/help.html、/helpabc.html、/help/index.html,而"Disallow:/help/"则允许robot访问/help.html、/helpabc.html,不能访问/help/index.html。"Disallow:"说明允许robot访问该网站的所有url,在"/robots.txt"文件中,至少要有一条Disallow记录。如果"/robots.txt"不存在或者为空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Allow:该项的值用于描述希望被访问的一组URL,与Disallow项相似,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头的URL 是允许robot访问的。例如"Allow:/hibaidu"允许robot访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一个网站的所有URL默认是Allow的,所以Allow通常与Disallow搭配使用,实现允许访问一部分网页同时禁止访问其它所有URL的功能。
使用"*"and"$":Baiduspider支持使用通配符"*"和"$"来模糊匹配url。
"*" 匹配0或多个任意字符
"$" 匹配行结束符。
最后需要说明的是:百度会严格遵守robots的相关协议,请注意区分您不想被抓取或收录的目录的大小写,百度会对robots中所写的文件和您不想被抓取和收录的目录做精确匹配,否则robots协议无法生效。
用发举例:
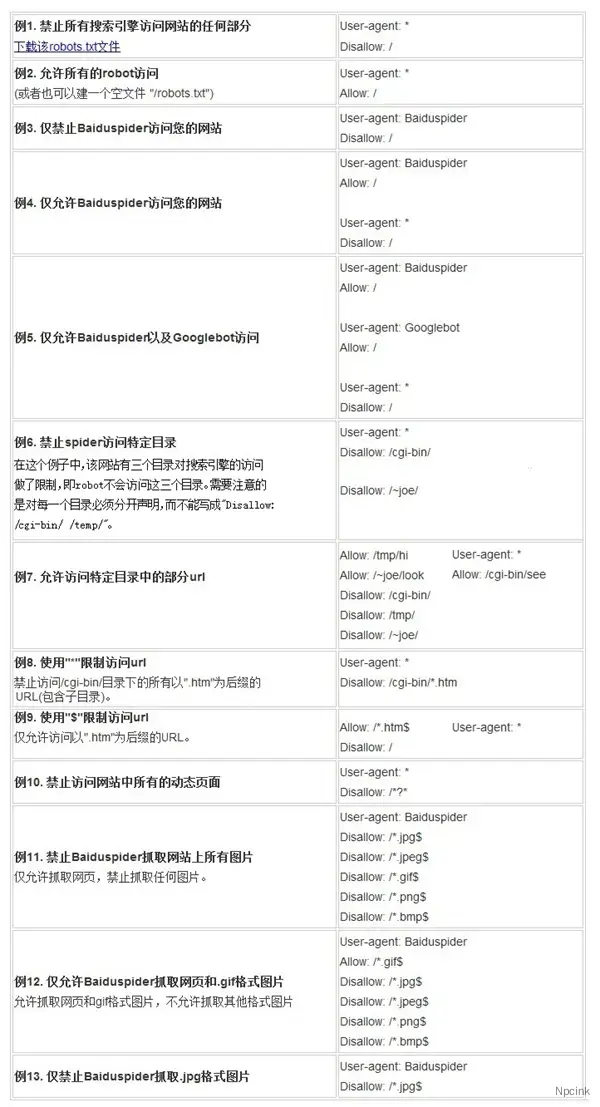
来源于:https://blog.csdn.net/aa3236925/article/details/78993924
但是在实际的操作中,绝大多数的网站,在其撰写上都存在或多或少的欠缺,甚至由于技术性的错误撰写,还会导致网站降权、不收录、被K等一系列问题的出现。对于这一点,A5营销,包括我,在对客户的SEO诊断过程中,会经常遇到,可以算是很多站点的通病。今天写出这篇文章,就是来做一个分享:关于robots.txt协议,你写对了吗?
一:设置成Allow全站点抓取
百度收录的越多,网站的排名越高?这是绝大多数站长的认为,事实上也是如此。但是也并非绝对成立:低质量的页面收录,会降低网站的排名效果,这一点你考虑到了吗?
如果你的网站结构不是非常的清晰,以及不存在多余的“功能”页面,不建议对网站开全站点的抓取,事实上,在A5的SEO诊断中,只遇到极少数的一部分网站,可以真正的做到全站点都允许抓取,而不做屏蔽。随着功能的丰富,要做到允许全站点抓取,也不太可能。
二:什么样的页面不建议抓取
对于网站功能上有用的目录,有用的页面,在用户体验上可以得到更好的提升。但是搜索引擎方面来讲,就会造成:服务器负担,比如:大量的翻页评论,对优化上则没有任何的价值。
除此外还包含如:网站做了伪静态处理后,那么就要将动态链接屏蔽掉,避免搜索引擎抓取。用户登录目录、注册目录、无用的软件下载目录,如果是静态类型的站点,还要屏蔽掉动态类型的链接Disallow: /*?* 为什么呢?我们举个例子来看:
上面是某客户网站发现的问题,被百度收录的原因是:有人恶意提交此类型的链接,但是网站本身又没有做好防护。
三:撰写上的细节注意事项
方法上来讲,绝大多数的站长都明白,这里就不做多说了,不明白的站长,可以上百度百科看一下。今天这里说一些不常见的,可能是不少站长的疑问。
1、举例:Disallow; /a 与Disallow: /a/的区别,很多站长都见过这样的问题,为什么有的协议后加斜杠,有的不加斜杠呢?笔者今天要说的是:如果不加斜杠,屏蔽的是以a字母开头的所有目录和页面,而后者代表的是屏蔽当前目录的所有页面和子目录的抓取。
通常来讲,我们往往选择后者更多一些,因为定义范围越大,容易造成“误杀”。
2、JS文件、CSS需要屏蔽吗?不少网站都做了这个屏蔽,但是笔者要说的是:google站长工具明确的说明:封禁css与js调用,可能会影响页面质量的判断,从而影响排名。而对此,我们做了一些了解,百度方面同样会有一定影响。
3、已经删除的目录屏蔽,很多站长往往删除一些目录后,怕出现404问题,而进行了屏蔽,禁止搜索引擎再抓取这样的链接。事实上,这样做真的好吗?即使你屏蔽掉了,如果之前的目录存在问题,那么没有被蜘蛛从库中剔除,同样会影响到网站。
建议最佳的方式是:将对应的主要错误页面整理出来,做死链接提交,以及自定义404页面的处理,彻底的解决问题,而不是逃避问题。